Изначально постил обзоры в этой теме, но там они уже затерялись, поэтому продублирую тут.
Недавно вышел X4 Foundation, где только вулкан рендер. И реализация рендера оставляет желать лучшего.Даже рендердок не может долго дебажить, где-то портится память и все перестает работать. vktrace тоже не работает.
Выдает всего 30фпс в 4к даже в пустом космосе...
Недостатки:
- general layout для depth buffer
- барьер включают абсолютно все этапы (src = ALL_COMMANDS, dst = ALL_COMMANDS) и они даже не сгруппированы, то есть может подряд идти 2 таких барьера
- а еще у всех барьеров стоит флаг DEPENDENCY_BY_REGION, что не имеет смысла
- шейдеры с дебажной инфой и плохо оптимизированны
- очень много дескриптор сетов
- SSAO в полном разрешении, причем нужен только для кабины, где все статично, можно было запечь АО и сэкономить 3мс.
воскресенье, 18 августа 2019 г.
Краткий обзор вулкан рендера в UE4
Изначально постил обзоры в этой теме, но там они уже затерялись, поэтому продублирую тут.
vkAcquireNextImage вызывается в отдельном потоке и принимает fence, его ожидание происходит в потоке рендера, похоже это такой способ сделать двойную/тройную буферизацию.
- многопоточногого рендера нету.
- постоянно вызывается vkCmdResetQueryPool, хотя в пул записывается время, которое сбрасывать не требуется, а на трансфер очереди такое не будет работать.
- постоянно копируется время из пула в host-visible память, но я не знаю насколько это плохо, я бы все же сделал отложенное копирование.
- дескриптор сеты сбрасываются каждый кадр, что тратит время цпу и очень плохо для мобилок.
- очень много дескриптор пулов, что не рекомендуется делать, (366 пулов в демке с частицами)
- 5 сабмитов на кадр, причем все в конце кадра, это не очень хорошо, так как сабмиты тяжелые.
- для каждого сабмита создается фенс, который потом нигде не используется.
- много подряд идущих барьеров, неплохо было бы их сгруппировать.
- симуляция частиц идет в фрагментном шейдере, вот это интересно.
- пустой рендер пасс для очистки текстуры, как было в doom.
- есть dynamic offset для буферов, но смысла в них нет, так как дескриптор сет не переиспользуется.
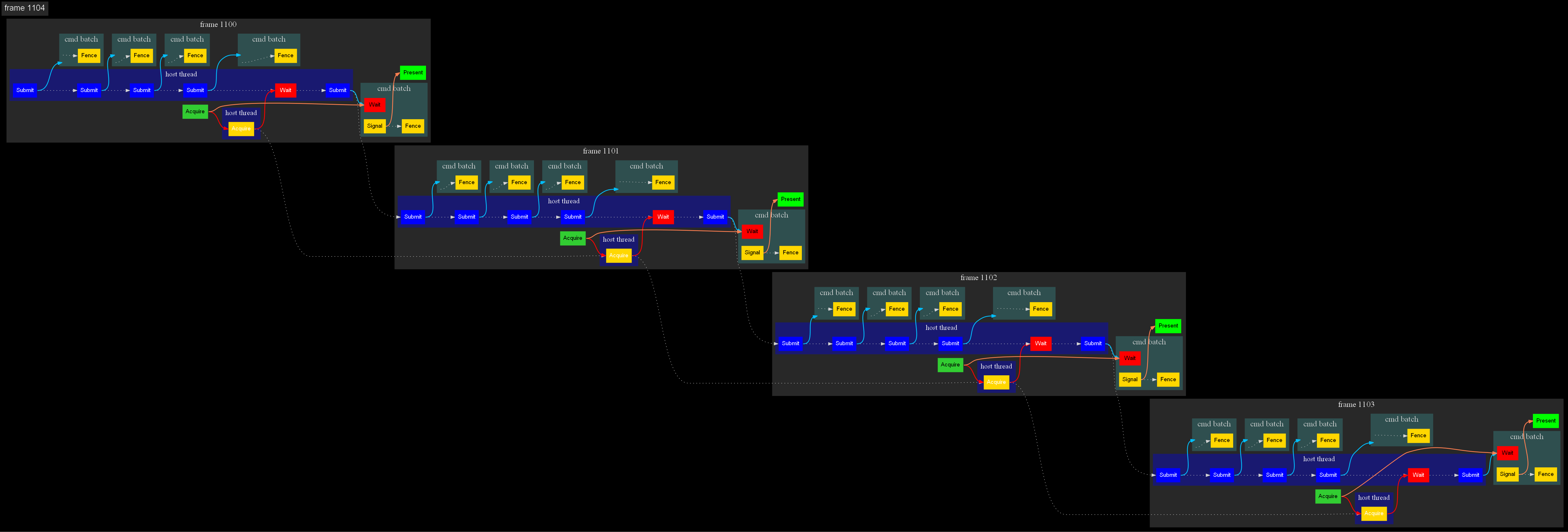
Граф синхронизаций.
Сконвертированный из трейса код кадра.
Почему на мобилках не рекомендуют сбрасывать дескриптор пулы: pdf
vkAcquireNextImage вызывается в отдельном потоке и принимает fence, его ожидание происходит в потоке рендера, похоже это такой способ сделать двойную/тройную буферизацию.
- многопоточногого рендера нету.
- постоянно вызывается vkCmdResetQueryPool, хотя в пул записывается время, которое сбрасывать не требуется, а на трансфер очереди такое не будет работать.
- постоянно копируется время из пула в host-visible память, но я не знаю насколько это плохо, я бы все же сделал отложенное копирование.
- дескриптор сеты сбрасываются каждый кадр, что тратит время цпу и очень плохо для мобилок.
- очень много дескриптор пулов, что не рекомендуется делать, (366 пулов в демке с частицами)
- 5 сабмитов на кадр, причем все в конце кадра, это не очень хорошо, так как сабмиты тяжелые.
- для каждого сабмита создается фенс, который потом нигде не используется.
- много подряд идущих барьеров, неплохо было бы их сгруппировать.
- симуляция частиц идет в фрагментном шейдере, вот это интересно.
- пустой рендер пасс для очистки текстуры, как было в doom.
- есть dynamic offset для буферов, но смысла в них нет, так как дескриптор сет не переиспользуется.
Граф синхронизаций.
{kind=link}
Сконвертированный из трейса код кадра.
Почему на мобилках не рекомендуют сбрасывать дескриптор пулы: pdf
суббота, 6 июля 2019 г.
VR эмулятор
На Windows обычно уже установлено приложение Mixed Reality Portal, в котором есть режим эмуляции девайса. Но для разработки под WMR придется использовать DirectX. К счастью есть совместимость с SteamVR, поэтому эмулятор можно использовать и при разработке для OpenVR на OpenGL/Vulkan/DirectX.
вторник, 2 июля 2019 г.
Что спрашивают на собеседованиях в геймдев
Архитектура CPU
Какой есть кэш и как работает, скорость доступа к памяти. Модели памяти weak vs strong.
Когда происходят кэш промахи.
Архитектура GPU
Как сгруппированы ядра: stream multiprocessor / compute unit, warp, какие особенности.
Как происходит растеризация, почему вытянутые треугольники это плохо (до перехода на tile based rendering).
Алгоритмы
Типичные вопросы по vector vs list, как работает map, unordered_map, что быстрее по сложности О и что лучше использует кэш. Как сделать быстрый поиск, как ускорить сортировку. Сложность алгоритмов.
Какие паттерны проектирования используются для оптимизации (ECS, DOD).
Какой есть кэш и как работает, скорость доступа к памяти. Модели памяти weak vs strong.
Когда происходят кэш промахи.
Архитектура GPU
Как сгруппированы ядра: stream multiprocessor / compute unit, warp, какие особенности.
Как происходит растеризация, почему вытянутые треугольники это плохо (до перехода на tile based rendering).
Алгоритмы
Типичные вопросы по vector vs list, как работает map, unordered_map, что быстрее по сложности О и что лучше использует кэш. Как сделать быстрый поиск, как ускорить сортировку. Сложность алгоритмов.
Какие паттерны проектирования используются для оптимизации (ECS, DOD).
Выделение памяти на стэке и на куче, в чем разница.
Алгоритмы рендеринга
Forward и deferred rendering, в чем различия, плюсы и минусы, какие оптимизации есть (tiled, clustered).
Physically based rendering в чем особенность, что такое BRDF, какие BRDF есть, в чем отличие.
Техники теней: shadow map, cascaded sm и тд. Фильтрация между каскадами.
Трассировка лучей: SSR, SDF shadows, volume rendering и тд.
Алгоритмы AA: supersampling, MSAA, MLAA, TAA и тд. Как сделать deferred shading с MSAA, как оптимизировать.
Многопоточность
Как получить deadlock. Какие примитивы синхронизации есть. Как работают атомики, что происходит с кэшем (надо расказать про memory order). Какая-нибудь задача на распараллеливание.
Математика
Векторное и скалярное произведение. Кватернионы. Как рассчитать OOBB. Как определить пересекается ли OOBB с frustum и как рассчитать экранные координаты. Задачи на геометрию.
C++
Вопросы про static, inline, virtual. Как работает виртуальная таблица, множественное наследование. Исключения. Move семантика. Плюсы и минусы стандартной библиотеки (stl).
Алгоритмы рендеринга
Forward и deferred rendering, в чем различия, плюсы и минусы, какие оптимизации есть (tiled, clustered).
Physically based rendering в чем особенность, что такое BRDF, какие BRDF есть, в чем отличие.
Техники теней: shadow map, cascaded sm и тд. Фильтрация между каскадами.
Трассировка лучей: SSR, SDF shadows, volume rendering и тд.
Алгоритмы AA: supersampling, MSAA, MLAA, TAA и тд. Как сделать deferred shading с MSAA, как оптимизировать.
Многопоточность
Как получить deadlock. Какие примитивы синхронизации есть. Как работают атомики, что происходит с кэшем (надо расказать про memory order). Какая-нибудь задача на распараллеливание.
Математика
Векторное и скалярное произведение. Кватернионы. Как рассчитать OOBB. Как определить пересекается ли OOBB с frustum и как рассчитать экранные координаты. Задачи на геометрию.
C++
Вопросы про static, inline, virtual. Как работает виртуальная таблица, множественное наследование. Исключения. Move семантика. Плюсы и минусы стандартной библиотеки (stl).
понедельник, 27 мая 2019 г.
Энергосбережение и профилирование
Видеокарты gtx 1070 в ноутбуке и RTX 2080 в ПК одинаково снижают частоты при рисовании простой графики. Таким образом, если кадр рисуется за 20мкс, то частоты снизятся так, чтобы кадр рисовался за 1-2мс. Обычно это даже хорошо - меньше нагрузка и соответственно меньше нагрев и меньше шума от вентиляторов. Но для замеров производительности это вносит огромные искажения. Теперь сложно оценить реальную скорость рисования/вычислений, остается только оценивать относительное время выполнения и то если частоты в этот момент не меняются.
Это касается замеров времени через FPS (количество кадров в секунду) и через встроенные в графические апи команды (например vkCmdWriteTimestamp в vulkan). RenderDoc для vulkan замеряет время именно таким способом, из-за чего результаты получаются некорректными. RenderDoc для DirectX 12 работает иначе и стабильно выдает корректное время. Профайлеры от производителей GPU тоже должны замерять время на максимальной частоте, но это надо проверять.
Как это можно обойти:
1. При запуске программы производительность максимальная, пока драйвер не обнаружит, что нагрузка небольшая и можно снизить частоты, обычно это занимает несколько секунд. В это время можно запускать тесты на производительность.
2. При увеличении нагрузки частоты также поднимаются. То есть можно сначала "прогреть" GPU, а потом делать точные замеры.
3. В NVAPI и в DX12 есть функция для установки стабильных частот на GPU.
понедельник, 13 мая 2019 г.
Anti-aliased SDF shadow
Пока делал volumetric light придумал как сделать anti-aliasing для теней и как раз попался простой пример с тенью в который я и добавил свой алгоритм.

Идея в том, чтобы при реймаршинге тени сохраняется история из трех последних результатов SDF функции и по ним обнаруживается паттерн вида \/ или \__ , это происходит когда луч проходит возле объекта, но не пересекается с ним. Минимальная дистанция до объектов сохраняется и используется для сглаживания тени.
воскресенье, 5 мая 2019 г.
Неявная оптимизация
В современных GPU есть множество разных оптимизаций, о которых не все знают.
Delta color compression
При рисовании в текстуру происходит сжатие данных без потерь, в глобальную память передается уже сжатые данные, что увеличивает пропускную способность памяти. Чтение текстуры в шейдере может работать со сжатыми данными, что немного увеличивает производительность. Но чтение/запись текстуры в вычислительном шейдере всегда приводит к разжатию данных, что отнимает некоторое время.
Некоторые форматы (например fp16) содержат слишком зашумленые данные, что снижает эффективность сжатия, поэтому иногда стоит использовать форматы с большей битностью (например fp32 вместо fp16), чтобы увеличить эффективность сжатия.
На Mali сжатие поддерживается только на RGBA8 формате.
На Adreno упоминаний про DCC нет, но есть хардварное сжатие которое работает для камеры, видео, RGB текстур и тд.
На Adreno упоминаний про DCC нет, но есть хардварное сжатие которое работает для камеры, видео, RGB текстур и тд.
Hardware occlusion culling
На данный момент реализовано в Nvidia и Mali.
Подробности о том, как это реализовано на Nvidia я не нашел. В idTech6, например, для Nvidia выключается GPU occlusion culling, потому что его заменяет хардварная реализация, для AMD он включен.
На новых Mali используется Visibility buffer. Первым проходом записывается только индекс вершины и инстанса и происходит тест глубины. Работает почти так же быстро как depth only pass. Далее идет проход по всем пикселям и для них выполняется вершиный шейдер для рассчета остальных аттрибутов, затем выполняется фрагментный шейдер. Для большей оптимизации рекомендуется хранить позиции вершин отдельно от остальных аттрибутов, так как они читаются в разных проходах.
Возможно в новых GPU от Intel также появится hardware occlusion culling также основанный на visibility buffer.
УAMD в патентах есть вариант с кулингом на вычислительных шейдерах, но реализации в железе пока нет.
Возможно в новых GPU от Intel также появится hardware occlusion culling также основанный на visibility buffer.
УAMD в патентах есть вариант с кулингом на вычислительных шейдерах, но реализации в железе пока нет.
Out of order rasterization
Обычно порядок в котором рисуются полигоны строго документирован, железо и драйвер могут вносить некоторые оптимизации, но это не должно влиять на результат. Для depth only pass порядок вывода примитивов не имеет значения, значит драйвер может рисовать их максимально эффективно.
На AMD эту оптимизацию можно включать вручную: link
Кэширование атомиков
На современных GPU есть быстрый кэш для нескольких атомиков, информации по Nvidia я не нашел, а в описании AMD по архитектуре GCN 3 говорится о кэше для 3х атомиках, если атомиков будет больше - будет работать заметно медленнее.
Android hardware scaling
В мобильных девайсах есть оптимизации для воспроизведения видео, например хардварное масштабирование изображения. Этот механизм можно использовать и для игр рисуя в свопчейн меньшего размера, вместо того чтоб делать масштабирование в шейдере это будет сделано в драйвере.
Подробное описание
Android hardware scaling
В мобильных девайсах есть оптимизации для воспроизведения видео, например хардварное масштабирование изображения. Этот механизм можно использовать и для игр рисуя в свопчейн меньшего размера, вместо того чтоб делать масштабирование в шейдере это будет сделано в драйвере.
Подробное описание
Graphics vs Compute
С появлением GPGPU видеокарты стали оптимизировать и для вычислительных задач, часто вычислительные шейдеры выполняются параллельно, если есть свободные ядра (CU) и между ними нет зависимости. Рисование работает иначе - только рисование в один фреймбуфер может быть распараллелено, это не очень эффективно, если размер фреймбуфера небольшой, тогда часть ядер простаивают. Вычислительные шейдеры не могут работать параллельно с рисованием. Для решения этой проблемы сначала AMD, а затем и Nvidia добавили async compute queue (только Vulkan и DX12), тогда рисование и вычисления могут выполняться параллельно.
Документация по Vulkan не запрещает параллельное рисование и параллельные вычисления с рисованием, это все ограничения железа и возможно скоро производители решат эту проблему.
Документация по Vulkan не запрещает параллельное рисование и параллельные вычисления с рисованием, это все ограничения железа и возможно скоро производители решат эту проблему.
понедельник, 29 апреля 2019 г.
Производительность некоторых операций на Vulkan
Просто проверка теории на практике.
Исходники тестов тут: GenMipmaps, ClearImage
Теория тут: Framebuffer compression, Delta color compression
Исходники тестов тут: GenMipmaps, ClearImage
Теория тут: Framebuffer compression, Delta color compression
понедельник, 4 марта 2019 г.
Разбор движка в Doom (2016)
Первая игра на idTech 6, здесь они впервые добавили поддержку Vulkan, но при этом было допущено не мало мелких ошибок и нарушений best practices, возможно в то время информации о Vulkan было не много и времени на исправления не хватило.
суббота, 2 февраля 2019 г.
Фичи и баги в Vulkan
1. Pipeline barrier'ы которые можно не ставить.
Однажды закоментил все барьеры и забыл про это, тесты на винде выполнялись на NVidia и Intel, но вот все тесты под линуксом на Intel выдавали ошибку. Оказалось, что драйвера под линукс более строго следят за инвалидацией кэша.
2. Async compute.
Разбил рисование на две очереди: graphics и compute, но не придумал как сделать синхронизацию между кадрами, решил оставить это на потом, так как на моей GTX1070 и так работает. А вот на RTX2080 получил race condition и битую картинку.
3. Повисание на создании пайплайна.
Сделал запись трейса шейдера, чтоб можно было его дебажить. Сначала все работало, но потом я сделал более детальный трейс и обновил драйвера, что-то из этого привело к повисанию при создании пайплайна с очень тяжелым шейдером, например рейтрейсом с шейдертоя.
4. Падение на рейтрейсе.
Опять проблема с трейсом шейдера для отладки. При записи в ray-gen шейдере получил device lost. Причем небольшие изменения в шейдере и все снова работает, а потом изменения в либе, которая добавляет запись в трейс, и снова падает.
5. Глючный андроид.
Никак не мог понять почему не создается инстанс на андроиде, выдает ошибку что слой валидации не поддерживается, но я не указал вообще ни одного слоя. Зато после перезагрузки телефона все запустилось.
понедельник, 14 января 2019 г.
Отладка шейдеров
До сих пор ситуация с дебагерами для шейдеров в основном печальная. В VS есть отладчик только для DirectX, не знаю точно поддерживается ли там 12, но 11 точно. В RenderDoc только DX11, для Vulkan есть декомпиляция SPIRV с помощью SPIRV-Cross. В NSight насчет DirectX не знаю, OpenGL там только просмотр шейдеров, если использовать бинарный формат, то не будет работать, для Vulkan даже просмотра дизасма SPIRV нет. Внезапно, Apple порадовал, с 31й минуты отладка шейдеров для Metal. В CUDA тоже много возможностей отладки и профилирования. Отладчиками от AMD я не пользовался из-за отсутствия видеокарты, но в расширениях GLSL есть функция timeAMD, как раз для профилирования, это можнт быть интересно. Единственный дебаггер для GLSL который я нашел не обновлялся уже 5 лет и поддержки Vulkan там точно нет.

Диаграмма из NSight смотрится красиво.
воскресенье, 13 января 2019 г.
среда, 9 января 2019 г.
FrameGraph. v0.6
Сделал промежуточный релиз фреймграфа и конвертера трейсов.

Главное достижение - я запустил трейс Doom на своем фреймграфе. Это было не то чтобы сложно, но были проблемные места. Например состояния, даже в вулкане они есть, это все вызовы vkCmdBind* и vkCmdSet*, при совместимых pipeline layout эти состояния сохраняются, при несовместимых инвалидируются, а мне нужно было получить все состояния для каждого DrawTask чтобы правильно его сконвертировать.
Далее более специфичная проблема - нужно было выкинуть оригинальный staging buffer и заменить его на таски UpdateBuffer и UpdateImage, для этого приходилось обнаруживать копирование из staging buffer в device local buffer/image, потом искать где этот участок памяти записывается в staging buffer и уже его передавать в таски фреймграфа. Тут возникла ошибка, когда я сконвертировал все буферы в device local и получил до 9 000 вызовов копирования, что занимало более 50% времени CPU и немалое время на GPU.
Возникли проблемы с сжатыми текстурами - у меня неправильно определялись диапазоны памяти и текстуры получались битыми. Еще обнаружился недостаток в рендерпассах - у меня не было поддержки readonly depth attachment и чтения текстуры в шейдере, для этого нужен был соответсвующий image layout, но проблема решилась достаточно быстро и я даже добавил это в тесты.
Моя система кэширования для descriptor set не выдержала стресс теста и постоянно переполнялась, пришлось задавать всем буферам динамическое смещение, я не заметил влияния на производительность, зато теперь с учетом резерва достаточно всего 64-128 дескриптор сетов.
Барьеры для текстур не проверяют диапазоны в 2D координатах, только слои и мипмэпы, поэтому например при копировании из staging buffer в текстуру вставляются лишние барьеры, но влияние на производительность я не заметил. Баг с излишним копированием в буферы позволил найти одно слабое место - расстановку барьеров для буферов, там учитываются все диапазоны и поиск пересечений может занять не мало времени. Решается это просто - большинство буферов судя по их usage - всегда readonly и только те что имеют usage staorage и transfer_dst могут измениться, соответственно только для них и расставляем барьеры.
Сама идея использования vktrace для тестов оказалась не очень удачной, потому что трейс Doom может занимать 11-70Гб в зависимости от наполнености сцены и того, как долго записывается трейс. Это очень много, если 11Гб на первом запуске еще может закэшироваться в оперативной памяти и все последующие запуски не будут упираться в скорость чтения с диска, то 70Гб уже ни куда не помещается и получить больше 10-20fps нереально.
Небольшие изменения в работе рендера связаные с переходом на фреймграф не оказали никакого влияния на время кадра, нужны более существенные изменения, чтобы как-то ускорить или замедлить рисование. Возможно я даже поэкспериментирую с оптимизацией, но это будет не скоро.
Подписаться на:
Сообщения (Atom)