Теоретизираю какой бы идеальный рендер граф я бы написал.
Показаны сообщения с ярлыком Vulkan. Показать все сообщения
Показаны сообщения с ярлыком Vulkan. Показать все сообщения
четверг, 14 июля 2022 г.
воскресенье, 15 мая 2022 г.
Как выбрать обертку над Vulkan
Написать качественную обертку над Vulkan совсем не просто, а учитывая количество расширений, особенностей драйверов и железа, то с первого раза это просто невозможно. Поэтому становится выбор либо потратить несколько лет на подробное изучение Vulkan и написание качественной обертки, которой сможет пользоваться кто-то незнакомый с Vulkan, либо найти уже готовую обертку. И тут оказывается, что не зная Vulkan найти хороший проект также нереально.
среда, 11 мая 2022 г.
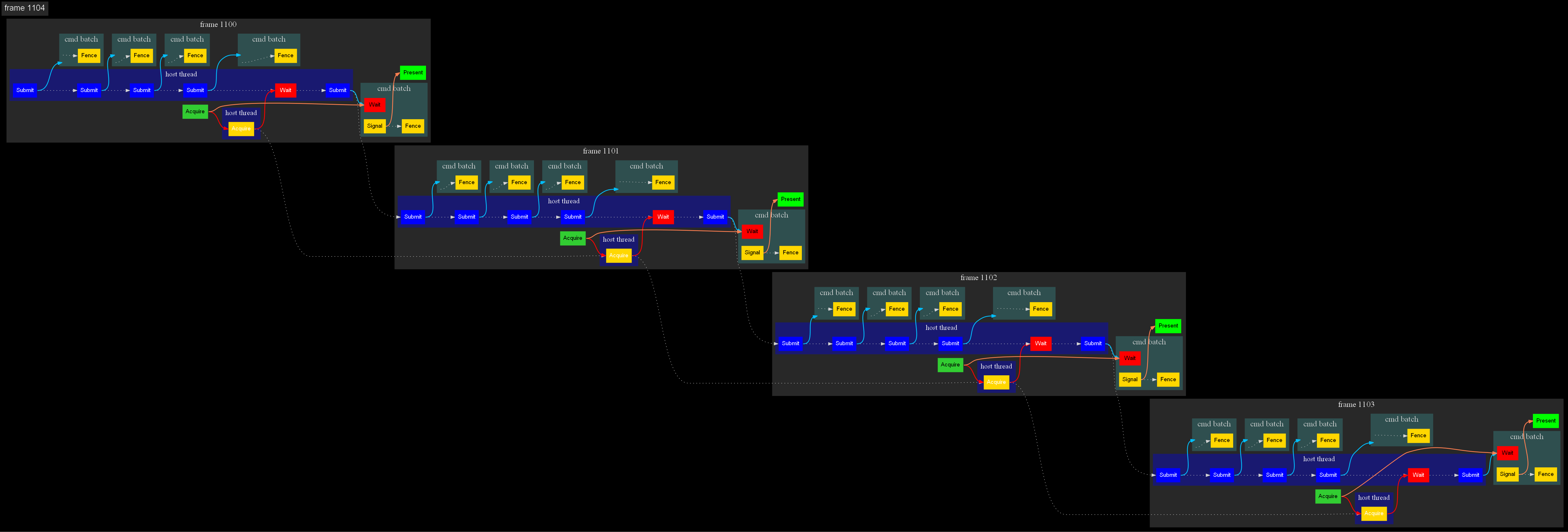
Нужен ли рендер граф? Часть 1
Еще в 2018-ом я написал свой FrameGraph, который был моей первой попыткой упростить работу с Vulkan, за полгода активной разработки синхронизации и многопоточность были полностью переделаны 3 раза. В последней версии FG стал достаточно гибким, чтобы автоматически расставлять синхронизации внутри очереди, а с небольшими подсказками от пользователя мог расставлять синхронизации между очередями. Это отлично работает для прототипирования, но нужно ли для больших проектов?
понедельник, 21 февраля 2022 г.
Как делается поддержка множества конфигураций железа
В DX большинство фич привязаны к версии API, а лимиты заданы константами в хэдере. В редких случаях есть параметры специфичные для железа, которые нужно запрашивать, но и они достаточно стандартизированы. К томуже количество конфигураций железа с поддержкой DX12 не так уж велико.
В Metal было несколько подходов, сначала был feature set, а потом его заменили на GPU family с Common/iOS/Mac семействами. Common задает общие фичи для всех конфигураций железа. Часть параметров также требуется запрашивать в рантайме. Сейчас свежее железо типа M1 и A14 имеет почти идентичные характеристики, что сильно упрощает разработку.
В Vulkan огромное количество фич и разнообразные лимиты, даже есть сайт, где можно посмотреть все конфиги: gpuinfo, также добавили слой device_simulation_layer, который частично эмулирует другие девайсы и упрощает тестирование.
воскресенье, 20 февраля 2022 г.
Особенности рендер пассов
Рендер пассы в Vulkan в основном нужны для оптимизации тайлового рендера в мобильных GPU (tile based deferred renderer), для этого в них используются сабпассы.
понедельник, 7 февраля 2022 г.
В чем проблема Vulkan on top of Metal
MoltenVk и некоторые другие проекты предоставляют возможность использовать Vulkan API поверх Apple Metal API, но внутри они содержат много неэффективного кода.
пятница, 4 февраля 2022 г.
среда, 26 января 2022 г.
Vulkan device simulation layer
Не все знаю и умеют правильно использовать этот слой для тестирования движка на разных конфигах железа.
Главное - этот слой всего лишь меняет информацию, возвращаемую драйвером, на новую, определенную в json. Таким образом слой валидации сможет обнаружить ошибки в использовании констант и в работе с некогерентной памятью.
Детальное описание можно прочитать здесь.
понедельник, 6 июля 2020 г.
Профилирование шейдеров
Не так давно в Vulkan появились расширения GL_ARB_shader_clock и GL_EXT_shader_realtime_clock, с их помощью можно получить время работы шейдера и время работы потока в сабгруппе.
воскресенье, 18 августа 2019 г.
Краткий обзор вулкан рендера в X4
Изначально постил обзоры в этой теме, но там они уже затерялись, поэтому продублирую тут.
Недавно вышел X4 Foundation, где только вулкан рендер. И реализация рендера оставляет желать лучшего.Даже рендердок не может долго дебажить, где-то портится память и все перестает работать. vktrace тоже не работает.
Выдает всего 30фпс в 4к даже в пустом космосе...
Недостатки:
- general layout для depth buffer
- барьер включают абсолютно все этапы (src = ALL_COMMANDS, dst = ALL_COMMANDS) и они даже не сгруппированы, то есть может подряд идти 2 таких барьера
- а еще у всех барьеров стоит флаг DEPENDENCY_BY_REGION, что не имеет смысла
- шейдеры с дебажной инфой и плохо оптимизированны
- очень много дескриптор сетов
- SSAO в полном разрешении, причем нужен только для кабины, где все статично, можно было запечь АО и сэкономить 3мс.
Недавно вышел X4 Foundation, где только вулкан рендер. И реализация рендера оставляет желать лучшего.Даже рендердок не может долго дебажить, где-то портится память и все перестает работать. vktrace тоже не работает.
Выдает всего 30фпс в 4к даже в пустом космосе...
Недостатки:
- general layout для depth buffer
- барьер включают абсолютно все этапы (src = ALL_COMMANDS, dst = ALL_COMMANDS) и они даже не сгруппированы, то есть может подряд идти 2 таких барьера
- а еще у всех барьеров стоит флаг DEPENDENCY_BY_REGION, что не имеет смысла
- шейдеры с дебажной инфой и плохо оптимизированны
- очень много дескриптор сетов
- SSAO в полном разрешении, причем нужен только для кабины, где все статично, можно было запечь АО и сэкономить 3мс.
Краткий обзор вулкан рендера в UE4
Изначально постил обзоры в этой теме, но там они уже затерялись, поэтому продублирую тут.
vkAcquireNextImage вызывается в отдельном потоке и принимает fence, его ожидание происходит в потоке рендера, похоже это такой способ сделать двойную/тройную буферизацию.
- многопоточногого рендера нету.
- постоянно вызывается vkCmdResetQueryPool, хотя в пул записывается время, которое сбрасывать не требуется, а на трансфер очереди такое не будет работать.
- постоянно копируется время из пула в host-visible память, но я не знаю насколько это плохо, я бы все же сделал отложенное копирование.
- дескриптор сеты сбрасываются каждый кадр, что тратит время цпу и очень плохо для мобилок.
- очень много дескриптор пулов, что не рекомендуется делать, (366 пулов в демке с частицами)
- 5 сабмитов на кадр, причем все в конце кадра, это не очень хорошо, так как сабмиты тяжелые.
- для каждого сабмита создается фенс, который потом нигде не используется.
- много подряд идущих барьеров, неплохо было бы их сгруппировать.
- симуляция частиц идет в фрагментном шейдере, вот это интересно.
- пустой рендер пасс для очистки текстуры, как было в doom.
- есть dynamic offset для буферов, но смысла в них нет, так как дескриптор сет не переиспользуется.
Граф синхронизаций.
Сконвертированный из трейса код кадра.
Почему на мобилках не рекомендуют сбрасывать дескриптор пулы: pdf
vkAcquireNextImage вызывается в отдельном потоке и принимает fence, его ожидание происходит в потоке рендера, похоже это такой способ сделать двойную/тройную буферизацию.
- многопоточногого рендера нету.
- постоянно вызывается vkCmdResetQueryPool, хотя в пул записывается время, которое сбрасывать не требуется, а на трансфер очереди такое не будет работать.
- постоянно копируется время из пула в host-visible память, но я не знаю насколько это плохо, я бы все же сделал отложенное копирование.
- дескриптор сеты сбрасываются каждый кадр, что тратит время цпу и очень плохо для мобилок.
- очень много дескриптор пулов, что не рекомендуется делать, (366 пулов в демке с частицами)
- 5 сабмитов на кадр, причем все в конце кадра, это не очень хорошо, так как сабмиты тяжелые.
- для каждого сабмита создается фенс, который потом нигде не используется.
- много подряд идущих барьеров, неплохо было бы их сгруппировать.
- симуляция частиц идет в фрагментном шейдере, вот это интересно.
- пустой рендер пасс для очистки текстуры, как было в doom.
- есть dynamic offset для буферов, но смысла в них нет, так как дескриптор сет не переиспользуется.
Граф синхронизаций.
{kind=link}
Сконвертированный из трейса код кадра.
Почему на мобилках не рекомендуют сбрасывать дескриптор пулы: pdf
понедельник, 29 апреля 2019 г.
Производительность некоторых операций на Vulkan
Просто проверка теории на практике.
Исходники тестов тут: GenMipmaps, ClearImage
Теория тут: Framebuffer compression, Delta color compression
Исходники тестов тут: GenMipmaps, ClearImage
Теория тут: Framebuffer compression, Delta color compression
понедельник, 4 марта 2019 г.
Разбор движка в Doom (2016)
Первая игра на idTech 6, здесь они впервые добавили поддержку Vulkan, но при этом было допущено не мало мелких ошибок и нарушений best practices, возможно в то время информации о Vulkan было не много и времени на исправления не хватило.
суббота, 2 февраля 2019 г.
Фичи и баги в Vulkan
1. Pipeline barrier'ы которые можно не ставить.
Однажды закоментил все барьеры и забыл про это, тесты на винде выполнялись на NVidia и Intel, но вот все тесты под линуксом на Intel выдавали ошибку. Оказалось, что драйвера под линукс более строго следят за инвалидацией кэша.
2. Async compute.
Разбил рисование на две очереди: graphics и compute, но не придумал как сделать синхронизацию между кадрами, решил оставить это на потом, так как на моей GTX1070 и так работает. А вот на RTX2080 получил race condition и битую картинку.
3. Повисание на создании пайплайна.
Сделал запись трейса шейдера, чтоб можно было его дебажить. Сначала все работало, но потом я сделал более детальный трейс и обновил драйвера, что-то из этого привело к повисанию при создании пайплайна с очень тяжелым шейдером, например рейтрейсом с шейдертоя.
4. Падение на рейтрейсе.
Опять проблема с трейсом шейдера для отладки. При записи в ray-gen шейдере получил device lost. Причем небольшие изменения в шейдере и все снова работает, а потом изменения в либе, которая добавляет запись в трейс, и снова падает.
5. Глючный андроид.
Никак не мог понять почему не создается инстанс на андроиде, выдает ошибку что слой валидации не поддерживается, но я не указал вообще ни одного слоя. Зато после перезагрузки телефона все запустилось.
понедельник, 14 января 2019 г.
Отладка шейдеров
До сих пор ситуация с дебагерами для шейдеров в основном печальная. В VS есть отладчик только для DirectX, не знаю точно поддерживается ли там 12, но 11 точно. В RenderDoc только DX11, для Vulkan есть декомпиляция SPIRV с помощью SPIRV-Cross. В NSight насчет DirectX не знаю, OpenGL там только просмотр шейдеров, если использовать бинарный формат, то не будет работать, для Vulkan даже просмотра дизасма SPIRV нет. Внезапно, Apple порадовал, с 31й минуты отладка шейдеров для Metal. В CUDA тоже много возможностей отладки и профилирования. Отладчиками от AMD я не пользовался из-за отсутствия видеокарты, но в расширениях GLSL есть функция timeAMD, как раз для профилирования, это можнт быть интересно. Единственный дебаггер для GLSL который я нашел не обновлялся уже 5 лет и поддержки Vulkan там точно нет.

Диаграмма из NSight смотрится красиво.
среда, 9 января 2019 г.
FrameGraph. v0.6
Сделал промежуточный релиз фреймграфа и конвертера трейсов.

Главное достижение - я запустил трейс Doom на своем фреймграфе. Это было не то чтобы сложно, но были проблемные места. Например состояния, даже в вулкане они есть, это все вызовы vkCmdBind* и vkCmdSet*, при совместимых pipeline layout эти состояния сохраняются, при несовместимых инвалидируются, а мне нужно было получить все состояния для каждого DrawTask чтобы правильно его сконвертировать.
Далее более специфичная проблема - нужно было выкинуть оригинальный staging buffer и заменить его на таски UpdateBuffer и UpdateImage, для этого приходилось обнаруживать копирование из staging buffer в device local buffer/image, потом искать где этот участок памяти записывается в staging buffer и уже его передавать в таски фреймграфа. Тут возникла ошибка, когда я сконвертировал все буферы в device local и получил до 9 000 вызовов копирования, что занимало более 50% времени CPU и немалое время на GPU.
Возникли проблемы с сжатыми текстурами - у меня неправильно определялись диапазоны памяти и текстуры получались битыми. Еще обнаружился недостаток в рендерпассах - у меня не было поддержки readonly depth attachment и чтения текстуры в шейдере, для этого нужен был соответсвующий image layout, но проблема решилась достаточно быстро и я даже добавил это в тесты.
Моя система кэширования для descriptor set не выдержала стресс теста и постоянно переполнялась, пришлось задавать всем буферам динамическое смещение, я не заметил влияния на производительность, зато теперь с учетом резерва достаточно всего 64-128 дескриптор сетов.
Барьеры для текстур не проверяют диапазоны в 2D координатах, только слои и мипмэпы, поэтому например при копировании из staging buffer в текстуру вставляются лишние барьеры, но влияние на производительность я не заметил. Баг с излишним копированием в буферы позволил найти одно слабое место - расстановку барьеров для буферов, там учитываются все диапазоны и поиск пересечений может занять не мало времени. Решается это просто - большинство буферов судя по их usage - всегда readonly и только те что имеют usage staorage и transfer_dst могут измениться, соответственно только для них и расставляем барьеры.
Сама идея использования vktrace для тестов оказалась не очень удачной, потому что трейс Doom может занимать 11-70Гб в зависимости от наполнености сцены и того, как долго записывается трейс. Это очень много, если 11Гб на первом запуске еще может закэшироваться в оперативной памяти и все последующие запуски не будут упираться в скорость чтения с диска, то 70Гб уже ни куда не помещается и получить больше 10-20fps нереально.
Небольшие изменения в работе рендера связаные с переходом на фреймграф не оказали никакого влияния на время кадра, нужны более существенные изменения, чтобы как-то ускорить или замедлить рисование. Возможно я даже поэкспериментирую с оптимизацией, но это будет не скоро.
четверг, 30 августа 2018 г.
FrameGraph. часть 2
Итак, первый этап разработки фреймграфа завершен, тесты написаны, картинка рисуется. Но похожих проектов уже несколько на гитхабе и намного больше в приватных репозиториях и в коммерческих проектах. Так как доказать, что мое решение лучше? А если не лучше, то как сделать его таковым?
Нужны тесты на производительность. Но писать их долго, тем более нужно с чем-то сравнивать и желательно с чистым вызовами vulkan api, да еще с наилучшей оптимизацией. Это конечно весело, но хочется побыстрее получить результат, поэтому я стал искать другие варианты и нашел - слой vktrace позволяет записывать все вызовы vulkan api и потом проигрывать их заново. Остается только конвертировать сохраненный трейс в C++ код с вызовом чистого vulkan api и с вызовом FrameGraph api, таким образом можно за короткое время получить множество тестов на производительность и корректность рендеринга (сравнивая кадры), да еще и не на простых демках, а на реальных играх и приложениях.
Подробнее о конвертере будет написано позже, сейчас идет только начальная стадия написания. В планах также добавить различные проходы оптимизации, что позволит увидеть потенциальный максимум производительности и сравнить его с текущим результатом, это будет полезно всем. Также хочу сравнить мой фреймграф с другими фреймворками и врапперами над вулканом, возможно сделаю opengl версию с максимальной оптимизацией, будет забавно сравнить фреймворки на вулкане с чистым opengl, особенно по нагрузке на cpu.
Кроме тестов на производительность, которые только будут, уже готовы юнит тесты, в том числе на правильную расстановку барьеров (которую на данный момент не осилили в VEZ). Написан встроенный дебагер и сериализатор кадра, которые используются для тестирования расстановки барьеров в сложной сцене, тестирования сортировки графа, тестирования оптимизации рендер пассов и тд. При сериализации кадра происходит сортировка ресурсов по имени, а не по хэшу указателя, как они обычно хранятся в мапе, что делает описание кадра независимым от запуска программы (когда меняется seed для хэша например).
Дополнительно дебагер обнаруживает возможные проблемы в при растановке барьеров, например ставятся подряд два барьера только на запись, это значит, что первый результат записи теряется, что скорее всего ошибка.
Дополнительно дебагер обнаруживает возможные проблемы в при растановке барьеров, например ставятся подряд два барьера только на запись, это значит, что первый результат записи теряется, что скорее всего ошибка.
FrameGraph. часть 1
Здесь будет рассказано о функциях фреймграфа: управление памятью, управление ресурсами, оптимизация кадра и тд.
Подписаться на:
Сообщения (Atom)