Ради эксперимента завел канал в телеграм для обзоров статей, конференций и тд.
Тематика та же: C++, графика, vulkan.
Преимущество такого формата - короткое описание с ссылкой на оригинал и тэги, это позволяет быстро найти нужную статью.
В DX большинство фич привязаны к версии API, а лимиты заданы константами в хэдере. В редких случаях есть параметры специфичные для железа, которые нужно запрашивать, но и они достаточно стандартизированы. К томуже количество конфигураций железа с поддержкой DX12 не так уж велико.
В Metal было несколько подходов, сначала был feature set, а потом его заменили на GPU family с Common/iOS/Mac семействами. Common задает общие фичи для всех конфигураций железа. Часть параметров также требуется запрашивать в рантайме. Сейчас свежее железо типа M1 и A14 имеет почти идентичные характеристики, что сильно упрощает разработку.
В Vulkan огромное количество фич и разнообразные лимиты, даже есть сайт, где можно посмотреть все конфиги: gpuinfo, также добавили слой device_simulation_layer, который частично эмулирует другие девайсы и упрощает тестирование.
Рендер пассы в Vulkan в основном нужны для оптимизации тайлового рендера в мобильных GPU (tile based deferred renderer), для этого в них используются сабпассы.
MoltenVk и некоторые другие проекты предоставляют возможность использовать Vulkan API поверх Apple Metal API, но внутри они содержат много неэффективного кода.
Не все знаю и умеют правильно использовать этот слой для тестирования движка на разных конфигах железа.
Главное - этот слой всего лишь меняет информацию, возвращаемую драйвером, на новую, определенную в json. Таким образом слой валидации сможет обнаружить ошибки в использовании констант и в работе с некогерентной памятью.
Детальное описание можно прочитать здесь.
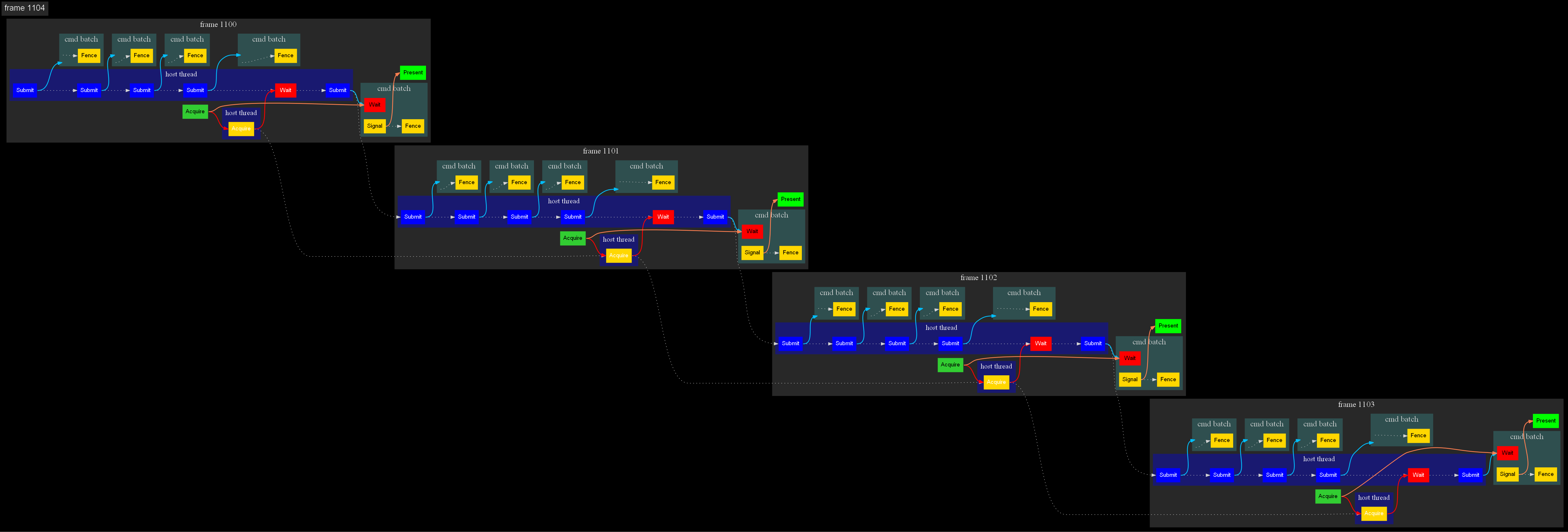
Пришло время оптимизировать очередь тасков для job/task system.
В идеале алгоритм выглядит так:


{kind=link}